Rule Tree learner
The training process of the Rule Tree classifier is divided into two steps.
In a preprocessing step, a set of conditions in the form of are determined for each explanatory variable.
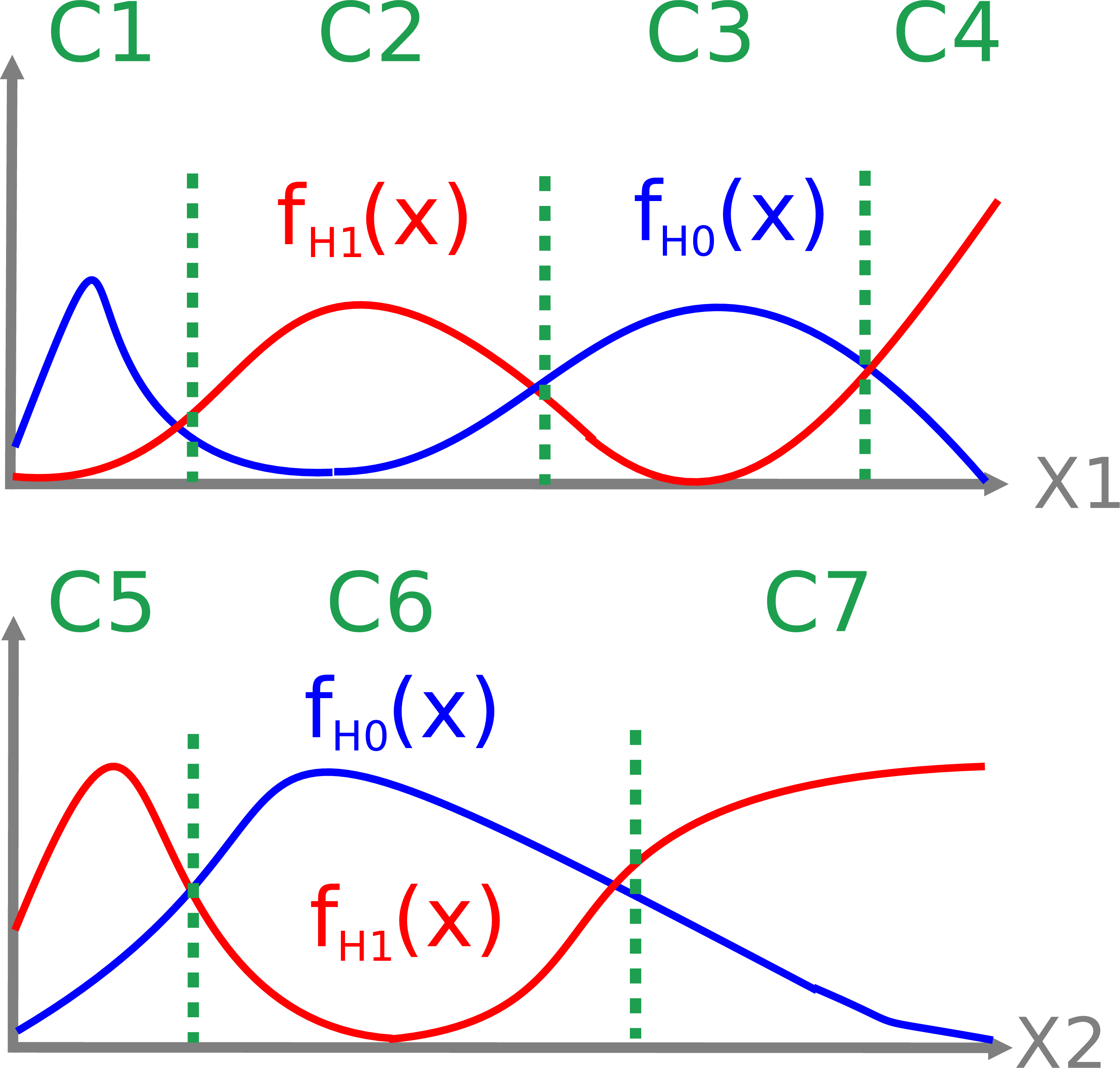
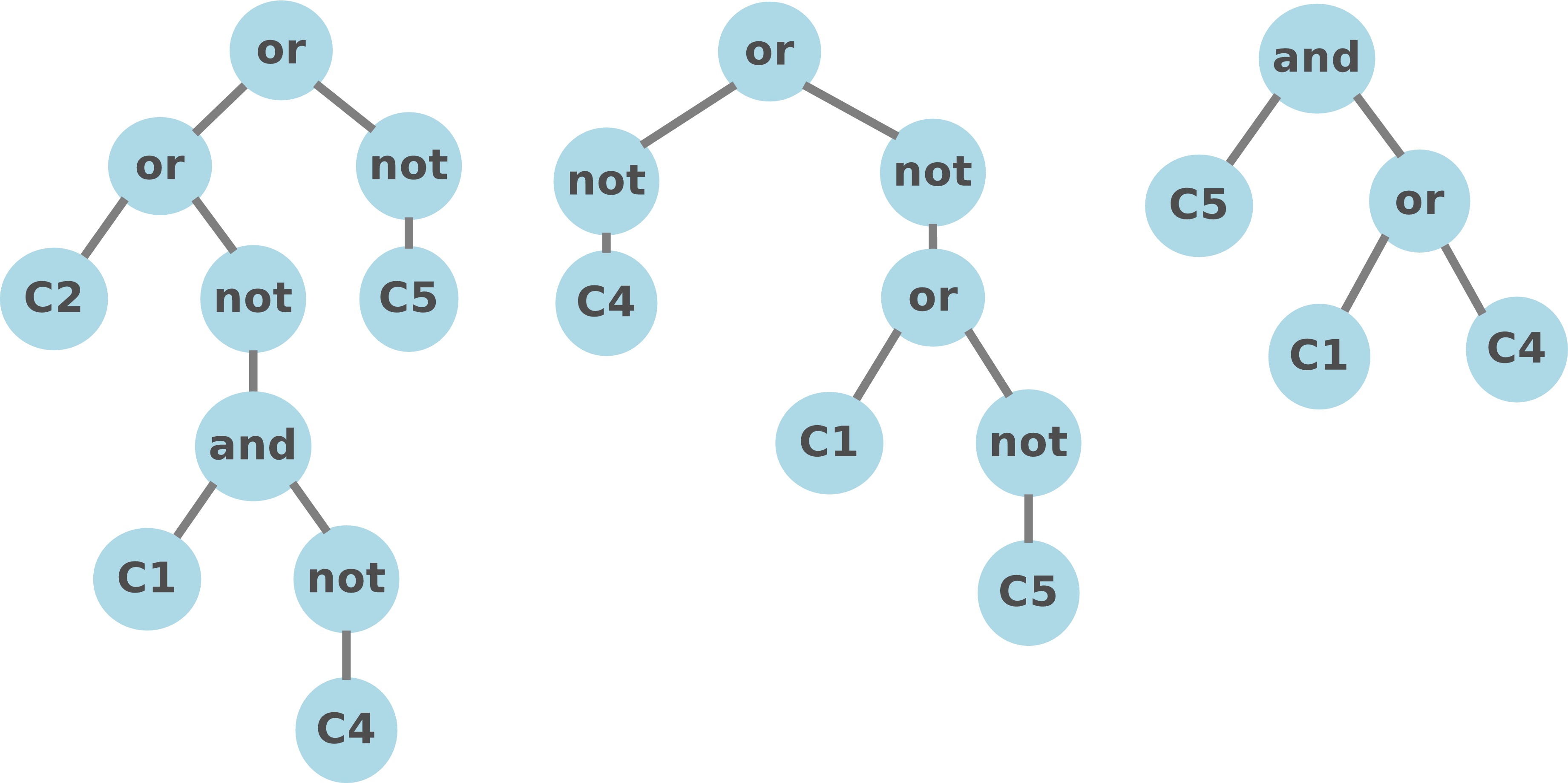
In the second step, a Genetic Programming strategy is adopted to search in the space of boolean rules using the generated conditions as leaves of the GP trees.
Current release provides functionality both for performing Binary Classification on numerical datasets and for testing the retrieved classifiers. In this page we provide a quick tutorial on how to get started with the Rule Tree learner. For further details of the Rule Tree classifier, the reader is referred to this paper:
Ignacio Arnaldo, Kalyan Veeramachaneni, Andrew Song, Una-May O’Reilly: Bring Your Own Learner! A cloud-based, data-parallel commons for Machine Learning. IEEE Computational Intelligence Magazine. vol.10, no.1, pp.20,32, Feb. 2015.
Tutorial
Note: this release is only supported for Linux Debian platforms.
Step 1: Data format
Data must be provided in csv format where each line corresponds to an exemplar and the 0 or 1 class labels are placed in the last column. Note that any additional line or column containing nominal values or labels needs to be removed.
Step 2: Download ruletree.jar file from here
Step 3: Running Rule Tree
In the current release, it is only possible to run the Rule Tree learner directly from your terminal (a Matlab wrapper will be included soon).
Running Rule Tree learner from the terminal
Obtaining a binary classifier
All you need to provide is the path to your dataset and the optimization time
$ java -jar ruletree.jar -train path_to_your_data -minutes 10
In a first step, the Rule Tree learner will divide the range of observed values of each variable into intervals. These intervals are reported in the file conditions.txt and will be used by the learner to construct boolean expressions. Note that current release only supports the following functions:
function_set = and or no
At the end of the run a set of files are generated:
pareto.txt: models forming the Pareto Front (accuracy vs model complexity).
leastComplex.txt: least complex model of the Pareto Front.
mostAccurate.txt: most accurate model of the Pareto Front.
knee.txt: model at the knee of the Pareto Front.
bestModelGeneration.txt: most accurate model per generation.
Test the classifiers
The ruleTree learner provides functionality to obtain the accuracy, precision, recall, F-score, false positive rate, and false negative rate of the retrieved classfiers once the training is finished. To automatically test all the generated classifiers, type:
$ cd run_folder
$ java -jar ruletree.jar -test path_data -conditions path_conditions
Running SR learner from Matlab
To be done
Bells and whistles
Change the default parameters
To modify the default parameters of the Rule Tree learner, it is necessary to append the flag -properties followed by the path of the properties file containing the desired parameters:
$ java -jar ruletree.jar -train path_to_your_data -minutes 10 -properties path_to_props_file
The following properties file example specifies the population size, the features that will be considered during the learning process, the functions employed to generate GP trees, the tournament selection size, and the mutation rate.
pop_size = 2000
function_set = or not
tourney_size = 10
mutation_rate = 0.1
Examples
To check reports visit our blog: FlexGP Blog
Authors and Contributors
FlexGP is a project of the Any-Scale Learning For All (ALFA) group at MIT.